Welcome to the Workshop on Polyhedral Geometry for Neural Networks
taking place on March 16–20 in the historic city of Nuremberg. The goal of the event is to bring together researchers interested in the connection between polyhedral geometry and the theory of neural networks.
Our workshop receives funding from the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) via priority programme SPP 2458 Combinatorial Synergies and via DFG project number 574350099.
Limited travel funds are available for young researchers.
If you have any questions, please write to
moritz.stargalla[at]utn.de
or any other organizer.
Our deadline to apply for funding support, contributed talks, and poster presentations has passed.
Caution: Scam emails about accommodation bookings for our workshop have been reported. Do not respond to these messages or share your details.
We welcome contributed talks and posters including short research pitches.
Adalbert Fono - LMU Munich
Adrian Göß - University of Technology Nuremberg
Alexander Martin - University of Technology Nuremberg
Alina Shubina - Johannes Kepler Universität Linz RICAM
Andreas Harth - FAU
Andrei Balakin - TU Berlin
Ansgar Freyer - FU Berlin
Arnau Padrol - Universitat de Barcelona
Ayush Kumar Tewari - RICAM Linz
Bella Finkel - University of Wisconsin-Madison
Blake Gaines - University of Connecticut
Chih-Chun Wang - LMU Munich
Egor Bakaev - University of Copenhagen
Florestan Brunck - University of Copenhagen
Florian Krowiorz - Brandenburgische Technische Universität Cottbus-Senftenberg
Francesco Nowell - TU Berlin
Giacomo Bais - Aalborg University
Günter Rote - Freie Universität Berlin
Hanna Wilhelm - OVGU Magdeburg
Himanshu Chandrakar - Indian Institute of Technology Bhilai
Hrishikesh V - Indian Institute of Technology, Bombay, India
Jakob Zimmermann - FU Berlin
Johanna Marie Gegenfurtner - Technical University of Denmark
Joscha Diehl - University of Greifswald
Julia Grübel - University of Technology Nuremberg
Kaelyn Willingham - University of Minnesota
Kamillo Ferry - TU Berlin
Katarina Krivokuća - FU Berlin
Kyle Huang - BTU Cottbus
Leo Zanotti - Ulm University
Lukas Koller - Technical University of Munich
Lyuhui Wu - Sorbonne Université
Manjot Singh - LMU Munich
Martin Winter - MPI Leipzig
Mateusz Skomra - LAAS-CNRS
Mei Han - TU Berlin
Moritz Grillo - MPI MIS Leipzig
Naima Elosegui Borras - Technical University of Denmark
Patrick Kobriger - Technical University of Munich
Roan Talbut - Durham University
Se Eun Choi - University of Osnabrueck
Thomas Kalinowski - Universität Rostock
Tilman Engel - Universität Rostock
Timm Oertel - FAU
Tobias Ladner - Technical University of Munich
Tom Baumbach - TU Berlin
William Jones - Cardiff University
Yaoying Fu - Boston College
Yuki Asano - University of Technology Nuremberg
Zhang Chen - Technische Universität Berlin
Zongpu Zhang - FU Berlin
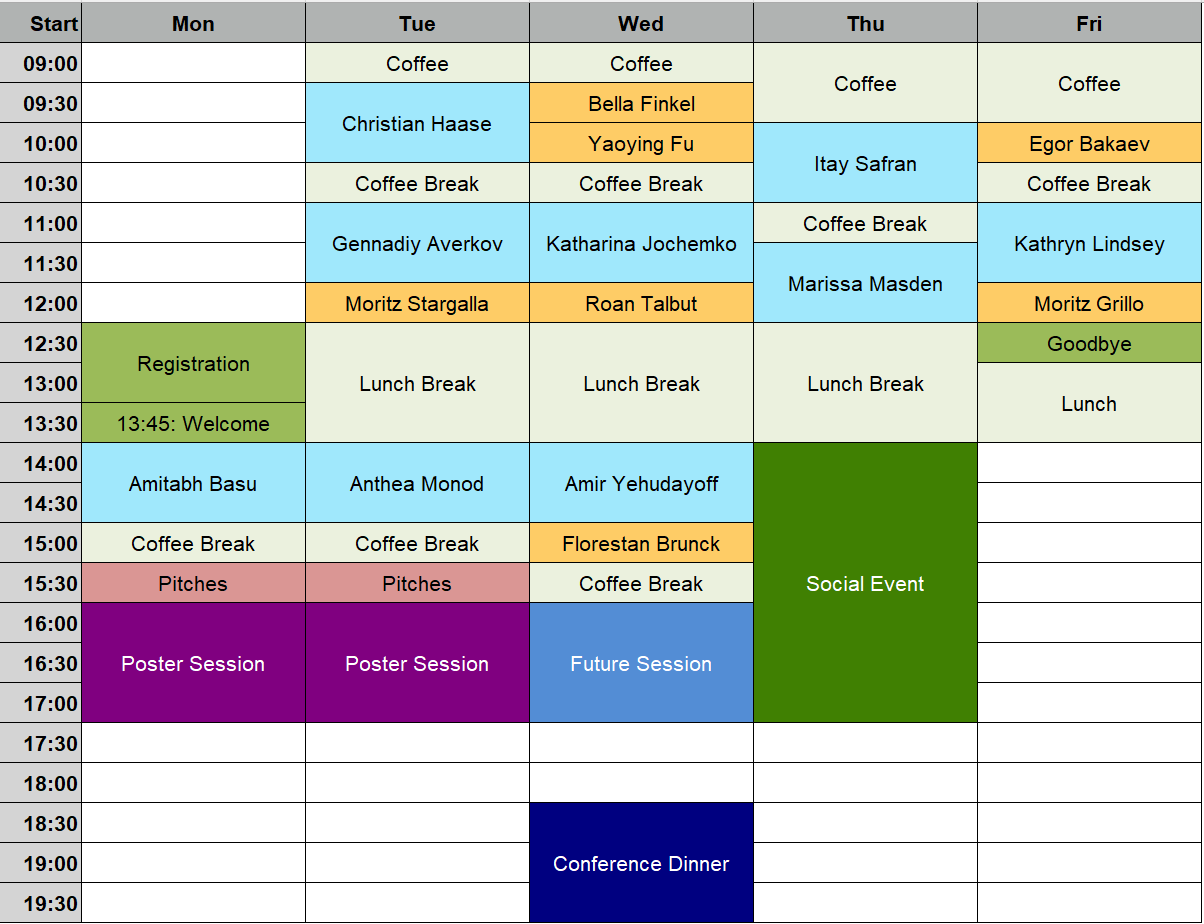
Schedule
Keynote Talks
Graph neural networks (GNNs) have been proposed as a way to detect patterns in data with graphical structures. GNNs can be bounded or unbounded, where bounded means that the size of the neural network is fixed a priori, and cannot be allowed to depend on the size of the graph that is being processed; on the other hand, unbounded GNNs use neural networks whose size is allowed to be a function of the size of the graph being processed. Until recently, it was not known if allowing unbounded size provably gives more power and was posed an open question by Martin Grohe. We show that this is indeed true as long as the activation functions are piecewise polynomials, generalizing an earlier result that established this for ReLU activations. We also show that the situation becomes considerably unclear when more general activations are allowed, such as sigmoid, tanh or other analytic nonpolynomial activations. The talk brings together ideas from discrete geometry, combinatorics, mathematical logic, transcendental number theory and neural networks.
Pitches + Posters
We illustrate which subsets of the real plane are realisable as the set of points on which a one-layer ReLU neural network takes a positive value. In the case of cones, we give a full characterisation of such sets. Furthermore, we give a necessary condition for any subset of R^d . We give various examples of such one-layer neural networks and interesting sets that could occur as positivity sets in the plane. (Based on joint work with Josef Schicho, Audie Warren, Alina Shubina, and Ayush Kumar Tewari)
We present a D6-equivariant vision transformer that takes input images defined on a hexagonal lattice and operates on a honeycomb lattice in intermediate layers. Feature maps are decomposed into irreducible representations of D3, instead of D6. In addition, a nonlinear layer is introduced, which makes use of all homogeneous spaces of D3 and alleviates the need of performing the Fourier transform over the entire group. We train and test our architecture on image classification datasets with natural rotational symmetry and find that similar performance as the baseline vision transformer architecture can be achieved with reduced number of parameters.
Introduced by Bayer et al. in the article “Perfect matching complexes of honeycomb graphs”, the perfect matching complex of a simple graph G is a simplicial complex having facets (maximal faces) as the perfect matchings of G. In this work, we discuss the perfect matching complex of polygonal line tiling, focusing particularly on the (2 × n)-grid graph. We utilize tools from discrete Morse theory and the fold lemma of independence complexes to demonstrate that the perfect matching complex of any polygonal line tiling is either contractible or homotopy equivalent to a wedge of spheres. While proving our results, we also characterize all the matchings that cannot be extended to form a perfect matching.
A flat loss manifold around a minimum is widely believed to promote generalisation, since the network output is more resilient to parameter and input perturbations, varying minimally in loss. The functional dimension – the number of independent directions in the parameter space along which the network changes – has been proposed as an indicator of flatness.
In this work we study how the functional dimension of the network is related to several other established measures of flatness. Furthermore, we investigate the impact of different optimizers, namely SGD, Adam, Natural Gradient Descent and Shampoo on the functional dimension, taking the initial steps to study the implicit bias of second order optimizers. In particular, we will focus on ReLU architectures, for which the parameter space symmetries are easy to disentangle from functionally meaningful directions.
Given a lattice polytope, it is natural to ask if it has a unimodular triangulation. Unimodular triangulations have connections to toric geometry, tropical geometry, and enumerative combinatorics, while also being an interesting property in their own right, for various classes of lattice polytopes. With the Julia package UniTriSat, we present a new algorithm for computing unimodular triangulations and regular unimodular triangulations, via translation to a SATISFIABILITY problem. This is joint work with Robert Lauff and Charlie Zhang.
Neural networks are ubiquitous. However, they are often sensitive to small input changes. Hence, to prevent unexpected behavior in safety-critical applications, their formal verification -- a notoriously hard problem -- is necessary. Many state-of-the-art verification algorithms use reachability analysis or abstract interpretation to enclose the set of possible outputs of a neural network. Often, the verification is inconclusive due to the conservatism of the enclosure. To address this problem, we propose a novel specification-driven input refinement procedure, i.e., we iteratively enclose the preimage of a neural network for all unsafe outputs to reduce the set of possible inputs to only enclose the unsafe ones. For that, we transfer output specifications to the input space by exploiting a latent space, which is an artifact of the propagation of a projection-based set representation through a neural network. A projection-based set representation, e.g., a zonotope, is a "shadow" of a higher-dimensional set -- a latent space -- that does not change during a set propagation through a neural network. Hence, the input set and the output enclosure are "shadows" of the same latent space that we can use to transfer constraints. We present an efficient verification tool for neural networks that uses our iterative refinement to significantly reduce the number of subproblems in a branch-and-bound procedure. Using zonotopes as a set representation, unlike many other state-of-the-art approaches, our approach can be realized by only using matrix operations, which enables a significant speed-up through efficient GPU acceleration. We demonstrate that our tool achieves competitive performance compared to the top-ranking tools of the international neural network verification competition.
Deploying neural networks for safety-critical railway monitoring demands provable safety guarantees, yet the high-dimensional, continuous input space of camera images makes formal verification computationally prohibitive for real-time use. We present a verification framework that precomputes unsafe regions of a network's input space offline, enabling efficient runtime safety checks via simple containment tests. Our approach consists of two stages. First, a deterministic dimensionality reduction pipeline localizes, transforms, and segments railway tracks into a standardized, low-dimensional representation. Second, a specification-driven iterative refinement algorithm, leveraging the latent space of zonotope set representations, partitions this reduced space to compute a guaranteed outer approximation of all input regions corresponding to unsafe network outputs. Experimental results on a five-dimensional input space show that after 80 refinement iterations, approximately 40% of the input space can be verified as safe, with refinement quality improvable by tuning the number of iterations, batch size, and initial set generators. The trained classifier achieves 100% recall, ensuring no truly unsafe images are missed.
Despite significant progress in post-hoc explanation methods for neural networks, many remain heuristic and lack provable guarantees. A key approach for obtaining explanations with provable guarantees is by identifying a cardinally-minimal subset of input features which by itself is provably sufficient to determine the prediction. However, for standard neural networks, this task is often computationally infeasible, as it demands a worst-case exponential number of verification queries in the number of input features, each of which is NP-hard. In this work, we show that for Neural Additive Models (NAMs), a recent and more interpretable neural network family, we can efficiently generate explanations with such guarantees. We present a new model-specific algorithm for NAMs that generates provably cardinally-minimal explanations using only a logarithmic number of verification queries in the number of input features, after a parallelized preprocessing step with logarithmic runtime in the required precision is applied to each small univariate NAM component. Our algorithm not only makes the task of obtaining cardinally-minimal explanations feasible, but even outperforms existing algorithms designed to find subset-minimal explanations -- which may be larger and less informative but easier to compute -- despite our algorithm solving a much more difficult task. Our experiments demonstrate that, compared to previous algorithms, our approach provides provably smaller explanations than existing works and substantially reduces the computation time. Moreover, we show that our generated provable explanations offer benefits that are unattainable by standard sampling-based techniques typically used to interpret NAMs.
We study the multigraded Betti numbers of Veronese embeddings of projective spaces. Due to Hochster's formula, we interpret these multigraded Betti numbers in terms of the homology of certain simplicial complexes. By analyzing these simplicial complexes and applying Forman's discrete Morse theory, we derive vanishing and non-vanishing results for these multigraded Betti numbers. This is joint work with Christian Haase.
Keynote Talks
This is the first in a series of three talks on the expressivity of ReLU neural networks of fixed depth but arbitrary width. I will explain the problem, and translate it into a question in polyhedral geometry. In this formulation, valuations play a key role in proving lower bounds.
As an appetizer application of these ideas, I want to convince you that it is impossible for a network with integral weights of depth $< \log_2(n)$ to compute the maximum of $n$ numbers.
How deep does a ReLU network need to be to reach its full expressive potential for a given number of inputs
n? At first glance, this might not seem like a geometric question - but it is, or at least it can be formulated as one. Likewise, it may not seem algebraic either, yet it becomes so once we consider that the weights live in a fixed domain, which is an algebraic structure. Thus, both algebra and geometry play crucial roles in understanding neural network depth. In this talk, I will focus on the role of the weight domain in analyzing ReLU depth, showing how the meeting of algebra and geometry leads to insights that are as fascinating as they are intricate.
Optimization trajectories in high-dimensional problems often concentrate on low-dimensional polyhedral structures while classical convergence analyses remain governed by global geometric constants of the ambient space. We develop a geometry-aware convergence framework based on trajectory-restricted regularity conditions. We show that for polyhedral optimization problems, linear convergence is controlled by restricted Hoffman constants associated with the polyhedral regions traversed by the algorithm. This perspective explains why optimization can remain fast even in highly overparameterized settings and provides a geometric lens through which polyhedral structure and algorithmic dynamics can be jointly understood. Joint work with Faris Chaudhry (Imperial College London) and Keisuke Yano (Institute of Statistical Mathematics, Japan).
Contributed Talks
Deciding injectivity of two-layer ReLU networks was recently shown to be fixed-parameter tractable in the input dimension, raising the question whether the same is true for other basic properties such as surjectivity. We answer this negatively for determining several properties (surjectivity, positivity, verification) of two-layer ReLU networks. We show that surjectivity relates to a more geometric problem: surjectivity reduces to positivity, which is itself a special case of verification; in the bias-free setting, positivity is equivalent to zonotope containment. We briefly discuss a parameterized reduction from the Multicolored Clique problem to positivity, which yields (conditional) runtime lower bounds for positivity, surjectivity, verification and zonotope containment. This talk is based on joint work with Vincent Froese, Moritz Grillo and Christoph Hertrich.
Pitches + Posters
Maxout polytopes are defined by feedforward neural networks with maxout activation function and non-negative weights after the first layer.
These polytopes can be constructed layer by layer from a finite set of points such that each subsequent polytope is a convex hull of two non-negative Minkowski combinations of polytopes from the previous layer.
For each fixed depth and layer sizes, one obtains a family of polytopes parametrized by the network weights. The poster explains why maxout polytopes are cubical for generic networks without bottlenecks.
A polytope is called indecomposable if it cannot be expressed (non-trivially) as a Minkowski sum of other polytopes. This poster introduces the graph of (implicit) edge dependencies and uses it to state a new indecomposability criterion that unifies and generalizes most of the previous techniques. One of our main applications is providing new indecomposable deformed permutahedra that are not matroid polytopes.
It is well established that ReLU networks define continuous piecewise-linear functions, and that their linear regions are polyhedra in the input space. These regions form a polyhedral complex that fully partitions the input space. The way these regions fit together is fundamental to the behavior of the network, as nonlinearities occur only at the boundaries where they connect. Building on previous work, we prove new results about the adjacency graph of top-dimensional regions of ReLU network complexes. We find that the average degree of this graph is upper bounded by twice the input dimension regardless of the width and depth of the network, and that the diameter of this graph has an upper bound that does not depend on input dimension, despite the number of regions increasing exponentially with input dimension. Experiments with networks trained on both synthetic and real-world data provide additional insight into the structure of these complexes.
The conditional independence (CI) relation of a distribution in a max-linear Bayesian network is fully determined by the combinatorics of critical paths in the underlying weighted graph. We call these CI structures maxoids, and prove that every maxoid can be obtained from a transitively closed weighted DAG. We show that the stratification of generic weight matrices by their maxoids yields a polyhedral fan which is the normal fan of the Minkowski sum of the Newton polytopes of path polynomials in the graph. The derived constructions and results form the basis for computational approaches to problems of enumeration and conditional independence implication. This is joint work with Tobias Boege, Kamillo Ferry and Ben Hollering
It has been demonstrated in various contexts that monotonicity leads to better explainability in neural networks. However, not every function can be well approximated by a monotone neural network. We demonstrate that monotonicity can still be used in two ways to boost explainability. First, we use an adaptation of the decomposition of a trained ReLU network into two monotone and convex parts, thereby overcoming numerical obstacles from an inherent blowup of the weights in this procedure. Our proposed saliency methods - SplitCAM and SplitLRP - improve on state of the art results on both VGG16 and Resnet18 networks on ImageNet-S across all Quantus saliency metric categories. Second, we exhibit that training a model as the difference between two monotone neural networks results in a system with strong self-explainability properties.
Transformers are the primary neural network architecture supporting large language models (LLMs) like ChatGPT, Claude and Google Gemini. Despite their ubiquity in the ML landscape today, a rigorous understanding of their underlying function remains elusive in many respects. In this work, we'll see how the geometry of shallow transformers with a determinantal layer attached connects very nicely to ranked-choice voting and partial permutation matrices through the use of tropical geometry.
The covering minima are classical parameters in Geometry of Numbers, interpolating between the reciprocal of the lattice width and the covering radius of a convex body. They were introduced by Kannan and Lovasz (1988) and further used to obtain the first polynomial bound on the flatness constant of Khinchine (1948). We give two new upper bounds on intermediate covering minima of general convex bodies, with a view towards a conjecture of Codenotti, Santos and Schymura (2021) on the maximal covering radius of a non-hollow lattice polytope.
Depth can be exponentially more efficient than width for representing some functions.
This advantage would be even stronger if shallow networks could always be simulated by deeper ones without superlinear parameter blowup.
I give a constructive 1D ReLU result showing that this is indeed true in a specific two-hidden-layer setting: for any fixed $\alpha\in(0,1)$, a width-n depth-3 network can be exactly represented by a deeper network with $O(n^\alpha)$ layers and width $O(n^{1-\tfrac{\alpha}{2}})$, thus keeping the total number of parameters at $O(n^2)$.
For $\alpha=\tfrac{1}{2}$, this complements the lower bound of Lu et al. (2017).
This talk is based on joint works with Omid Amini and Matthieu Piquerez.
We study convex functions on polyhedral spaces. We define a convex function on a polyhedral space as a continuous function that admits a local affine support function at
each point. This class of convex functions turns out to coincide with the class introduced by Botero-Burgos-Sombra. We present several convex-analytic results, including a regularization theorem stating that every convex function on a polyhedral space can be uniformly approximated by piecewise linear convex functions.
The synergy between spiking neural networks and neuromorphic hardware holds promise for the development of energy-efficient AI applications. Inspired by this potential, we revisit the foundational aspects to study the capabilities of spiking neural networks where information is encoded in the firing time of neurons. Under the Spike Response Model as a mathematical model of a spiking neuron with a linear response function, we compare the expressive power of artificial and spiking neural networks. We provide complexity bounds on the size of spiking neural networks to emulate multi-layer (ReLU) neural networks. Moreover, we also derive upper and lower bounds on the number of linear regions in the case of SNNs.
Keynote Talks
We consider binary classification restricted to a class of continuous piecewise
linear functions whose decision boundaries are (possibly nonconvex) starshaped
polyhedral sets, supported on a fixed polyhedral simplicial fan. We investigate
the expressivity of these function classes and describe the combinatorial and
geometric structure of the loss landscape, most prominently the sublevel sets, for
two loss-functions: the 0/1-loss (discrete loss) and a log-likelihood loss function.
In particular, we give explicit bounds on the VC dimension of this model, and
concretely describe the sublevel sets of the discrete loss as chambers in a hyperplane
arrangement. For the log-likelihood loss, we give sufficient conditions for the
optimum to be unique, and describe the geometry of the optimum when varying
the rate parameter of the underlying exponential probability distribution.
This is joint work with Marie-Charlotte Brandenburg.
Following the previous talks, we know that good partitions of the simplex lead to low depth representations of the maximum function. In this talk, we shall explore this idea further, demonstrate by examples, and search in higher dimensional space.
Contributed Talks
Polynomial neural networks are implemented in a range of applications and present an advantageous framework for theoretical machine learning. In this talk, we will discuss the expressive power of deep polynomial neural networks through the geometry of their neurovariety. In particular, we introduce the notion of the activation degree threshold of a network architecture to determine when the dimension of a neurovariety achieves its theoretical maximum. We show that activation degree thresholds of polynomial neural networks exist and provide an upper bound, resolving a conjecture of Kileel, Trager and Bruna on the dimension of neurovarieties associated to networks with high activation degree. Certain structured architectures have exceptional activation degree thresholds, making them especially expressive in the sense of their neurovariety dimension. In this direction, we discuss a proof that polynomial neural networks with equi-width architectures are maximally expressive.
Understanding the mathematical foundation of machine learning theory has become essential in this ever changing world of AI. In particular, neural networks with Rectified Linear Unit (ReLU) activations underlie almost every other machine learning problem. In this talk, I will develop a dictionary between feedforward ReLU neural networks and toric geometry. The central insight underlying this work is that the function computed by a feedforward ReLU neural network with no biases can be interpreted as the support function of a Q-Cartier divisor on a rational polyhedral fan. This work also reveals a link between the tropical geometry and the toric geometry of ReLU neural networks: the toric geometry can be viewed as a lift of the tropical geometry, in which the underlying geometric structure (toric geometry) is recovered from the combinatorial data (tropical geometry). With the toric geometry framework, we prove a necessary and sufficient criterion of functions realizable by unbiased shallow ReLU neural networks by computing intersection numbers of the ReLU Cartier divisor and torus-invariant curves. With time permitting, I will discuss ongoing work involving the nef cone of the ReLU toric variety, which offers insight into how network depth influences expressivity.
Fréchet means are a popular type of average for non-Euclidean datasets, defined as those points which minimise the sum squared distance to a set of datapoints. In this talk, we discuss the behaviour of sample Fréchet means on normed spaces whose unit ball is a polytope, a setting with direct applications to phylogenetic tree data analysis. This setting is rarely covered by existing literature on Fréchet means, which focuses on smooth spaces or spaces with bounded curvature. We study the geometry of the set of Fréchet means over polytope normed spaces, with a focus on dimension and probabilistic conditions for uniqueness. In particular, we study the threshold sample size at which Fréchet means have a positive probability of being unique.
Hertrich conjectured that $\log_2(n)$ layers were necessary to compute the maximum of $n$ elements exactly. While progress had been made towards confirming this conjecture in various restricted settings, we recently disproved this conjecture in the general setting and brought down the upper bound to $\log_3(n)$. While it is now unclear what the correct lower bound should be, it is certainly remarkable that no better lower bound than 2 is known in the general setting. Geometrically, the depth 2 picture is both rich and simple: if the simplex can be partitioned into pieces that are each free joins of zonotopes, then 2 is a matching lower and upper bound. In a recent bout of skepticism, and to make progress towards perhaps a non constant lower bound, we show together with Jack Stade and Amir Yehudayoff that, in dimensions > 3, whatever this partition may be, it must either involve pieces which are more complicated than zonotope pyramids (joins of a point with a zonotope) or else necessary be a non-proper partition.
Keynote Talks
In this talk, we will explore depth-width tradeoffs for approximating the maximum function in ReLU neural networks. We will investigate these tradeoffs through three distinct lenses of approximation: exact computation, achieving arbitrarily good accuracy for a fixed architecture via weight-scaling alone, and achieving exponentially small error. We will survey the landscape of lower and upper bounds to demonstrate how varying the accuracy requirements fundamentally alters the required network size, culminating in a novel lower bound for exact computation, which establishes that any constant-depth network requires super-linear width.
The polyhedral decomposition that ReLU neural networks impose on their input space is closely tied to their functional expressivity. We discuss the Sign Sequence characterization of the canonical polyhedral complex of ReLU neural networks, as defined by Grigsby & Lindsey (2022) and characterized by M (2025). This characterization is useful for encoding topological properties of a given network function, and we discuss its theoretical properties, issues surrounding its computation, and its utility in accessing PL and Discrete Morse measures of function complexity.
Keynote Talks
Neural networks can represent a wide variety of functions, and typically they do so redundantly: many distinct parameter settings correspond to the same function. I will discuss this redundancy via the fiber of a function—the set of all parameters that realize it—in deep linear networks and fully connected ReLU networks. I will describe the geometry of these fibers, including the quotient structure induced by symmetry and the resulting stratified foliation of parameter space. For deep linear networks, I will discuss balanced representations and their role within this geometry. In the ReLU setting, I will relate fiber structure to the polyhedral decomposition determined by activation patterns. I will conclude by indicating how these geometric features bear on expressivity and the implicit regularization induced by training dynamics.
Contributed Talks
We study approximations of polytopes in the standard model for computing polytopes using Minkowski sums and (convex hulls of) unions. Specifically, we study the ability to approximate a target polytope by polytopes of a given depth. Our main results imply that simplices can only be ``trivially approximated''. On the way, we obtain a characterization of simplices as the only ``outer additive'' convex bodies.
In this talk, we address the open question of how many hidden layers are necessary for ReLU networks to exactly represent all continuous piecewise linear functions. While the general lower bound remains 2, we focus on networks compatible with certain polyhedral complexes, specifically the braid fan. For these networks, we prove a non-constant lower bound on the number of hidden layers required to exactly represent the maximum of d numbers. This shows that, for such networks, the minimal depth grows with the input size.
This talk is based on joint work with Christoph Hertrich and Georg Loho
The conference dinner will take place on Wednesday at 6:30 p.m. at the Mautkeller Brewhouse on a self-pay basis.
You can have a look at their evening menu here.
We will walk from the workshop venue towards the city center (approximately 10 kilometers).
The tour will take place regardless of weather conditions.
We recommend that you wear weather-appropriate clothing and shoes, as forest paths can be muddy at this time of year.